Pandas makes it easy to scrape a table (<table> tag) on a web page. After obtaining it as a DataFrame, it is of course possible to do various processing and save it as an Excel file or csv file.
In this article you'll learn how to extract a table from any webpage. Sometimes there are multiple tables on a webpage, so you can select the table you need.
Practice now: Test your Python skills with interactive challenges
Pandas web scraping
Install modules
It needs the modules lxml, html5lib, beautifulsoup4. You can install it with pip.
$ pip install lxml html5lib beautifulsoup4
pands.read_html()
You can use the function read_html(url) to get webpage contents.
The table we'll get is from Wikipedia. We get version history table from Wikipedia Python page:
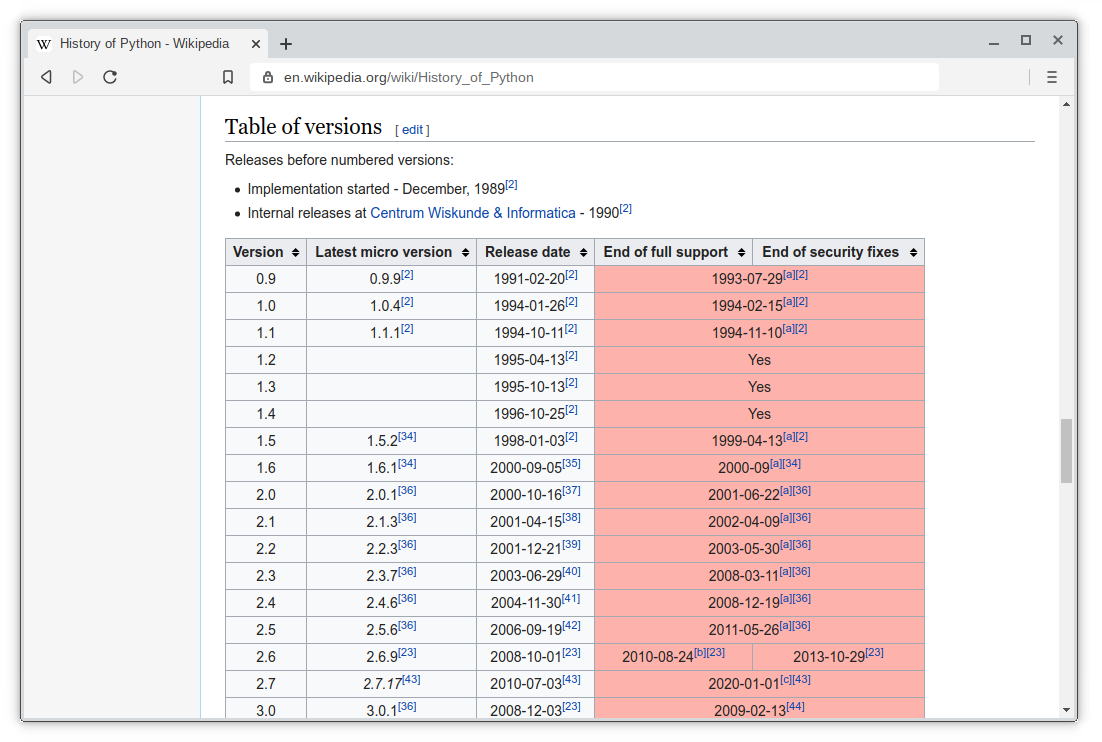
import pandas as pd
url = 'https://en.wikipedia.org/wiki/History_of_Python'
dfs = pd.read_html(url)
print(len(dfs))
This outputs:
1
Because there is one table on the page. If you change the url, the output will differ. To output the table:
print(dfs[0])
You can access columns like this:
print(dfs[0]['Version'])
print(dfs[0]['Release date'])
Pandas Web Scraping
Once you get it with DataFrame, it's easy to post-process. If the table has many columns, you can select the columns you want. See code below:
# Load pandas
import pandas as pd
# Webpage url
url = 'https://en.wikipedia.org/wiki/History_of_Python'
# Extract tables
dfs = pd.read_html(url)
# Get first table
df = dfs[0]
# Extract columns
df2 = df[['Version','Release date']]
print(df2)
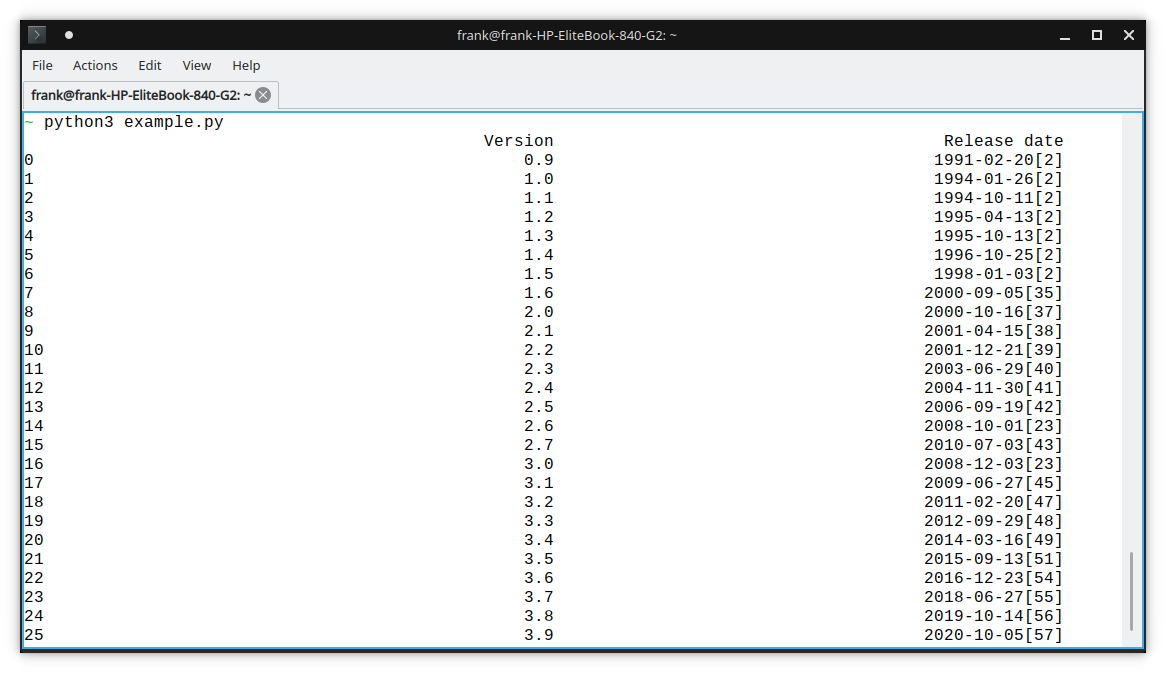
Then you can write it to Excel or do other things:
# Write to excel
df2.to_excel('python.xlsx')
Practice now: Test your Python skills with interactive challenges